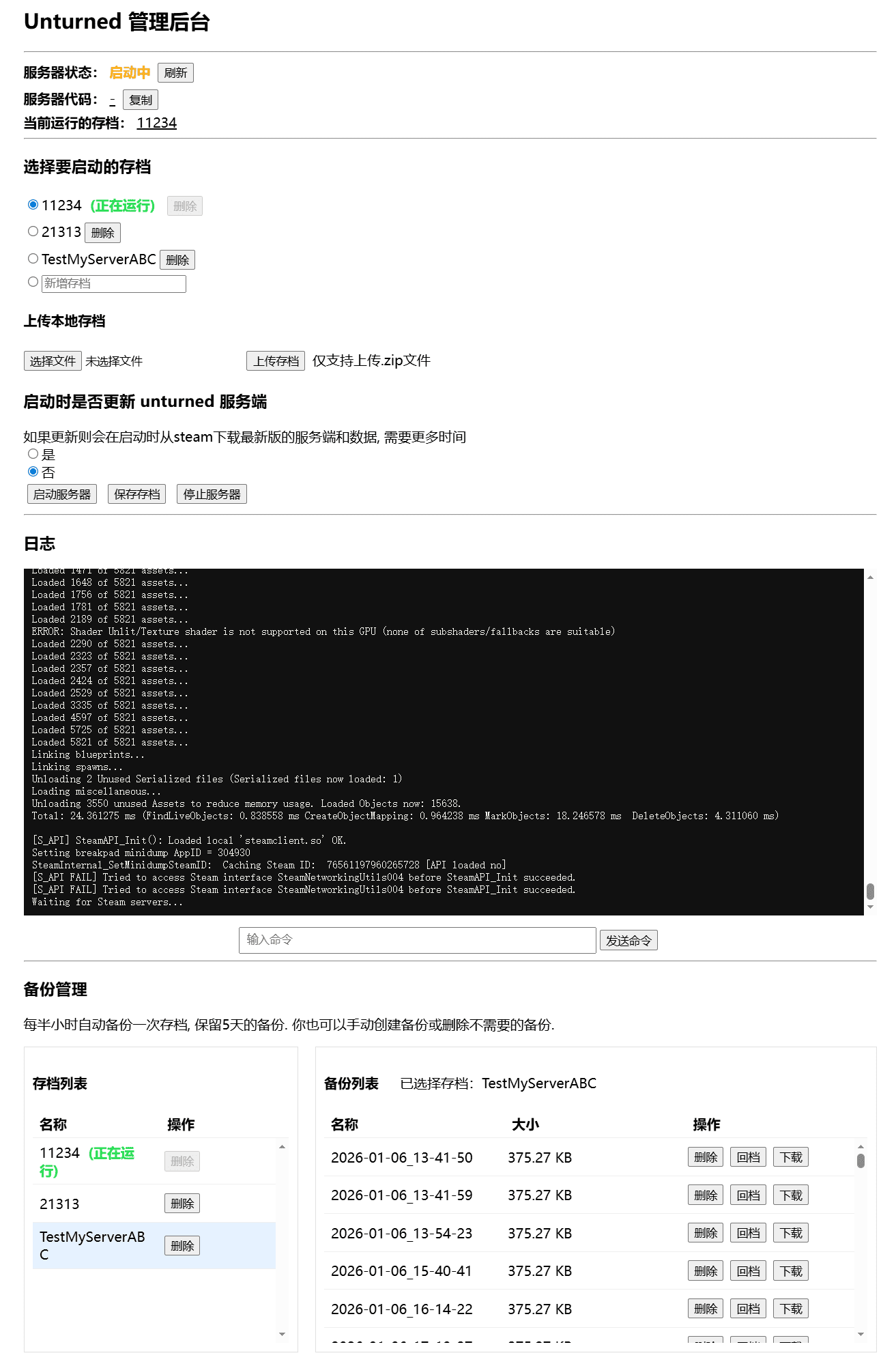
搭建简易的unturned游戏服务器管理界面
1. 前言
我想做一个简易的unturned游戏服务器管理界面,方便自己和朋友们管理游戏服务器。借助 AI 工具和自己的一些前后端知识,最终实现了这个目标。本文将分享我的开发过程和一些关键代码。
项目地址: https://github.com/lxmghct/unturned-server
2. 技术栈
- 后端: Flask + Flask-SocketIO
- 前端: HTML + CSS + JavaScript (axios + socket.io)
3. 整体架构设计
这个管理后台的核心目标很简单:通过 Web 界面控制一个在 Linux 上运行的 Unturned 专用服务器。
整体架构如下:
浏览器
↓ (HTTP + Password Header)
Flask 后端
↓
tmux 会话
↓
Unturned 服务端进程
核心思想是:
- Web 不直接管理进程
- 所有服务器生命周期都交给 tmux
- 后端只是作为一个“控制层”和“状态解析层”
这样做的好处是:
- 即使 Flask 崩溃,服务器仍然在 tmux 中运行
- 服务器和 Web 管理面板完全解耦
- 不需要写复杂的进程守护逻辑
使用 tmux 的好处在于它天然支持交互式控制台程序,可以方便地向 unturned 开服脚本打开的寄生终端发送命令,并且可以随时获取日志输出。
4. 服务器状态管理
4.1. 服务器状态识别机制
主要需要获取的信息有两个,即服务器的 Server Code 和当前激活的存档(Active Save)。 Unturned 启动后会在控制台输出:
Server Code: XXXXX
Workshop install folder: /home/.../Servers/xxx/
不过考虑到获取当前存档并不依赖于日志,实际上在启动脚本时就可以知道当前存档名称。所以后续我在启动脚本中加入了一行:
echo "Using active_save: $active_save"
这样直接读取日志第一行就能获取当前存档。
4.2. 状态分类
服务器状态定义为三种:
| 状态 | 含义 |
| 0 | 未运行 |
| 1 | 启动中(tmux存在但未解析到Server Code) |
| 2 | 运行中(tmux存在且已解析到Server Code) |
判断逻辑:
if not session_exists:
status = 0
elif session_exists and not server_code:
status = 1
else:
status = 2
4.3. 状态获取与持久化
一个关键问题:服务器启动需要时间,Server Code 不是立即出现。
4.3.1. 第一版解决方案
启动服务器后,开一个后台线程,每秒抓取一次 tmux 输出,直到解析到 Server Code。
def tmux_capture():
result = subprocess.run(
["tmux", "capture-pane","-S", "-32767", "-t", TMUX_SESSION, "-p"], capture_output=True,
text=True
)
return result.stdout
def wait_for_server_code():
while True:
output = tmux_capture()
server_code = extract_server_code(output)
...
time.sleep(1)
线程只在需要时启动:
def start_waiting_thread():
if waiting_thread is None or not waiting_thread.is_alive():
...
最后存储到全局变量:
server_status = {
"server_code": None,
"active_save": None
}
由于后端和 tmux 是解耦的,Flask 重启会丢失这个状态,所以需要存储到文件里以便下次恢复。
STATUS_FILE = "data/server-status.txt"
# 当解析到 Server Code 后:
save_status_to_file(server_code, active_save)
# Flask 启动时:
if tmux_session_exists():
load_status_from_file()
缺点: 日志文件较大时会丢失部分重要信息,导致无法正确解析 Server Code。且日志较大时性能较差。前端不能过于频请求状态,否则会影响性能,因此前端状态不能及时更新。
4.3.2. 第二版改进方案
主要有两点改进:
- tmux 的输出重定向到一个单独的日志文件,Flask 只读取这个日志文件,避免读取大量无关日志。
- 使用 Flask-SocketIO 实现状态的实时推送,避免前端频繁轮询。
启动脚本中添加:
tmux pipe-pane -o "cat >> $log_path"
def _read_log_pipe_thread():
"""读取日志管道内容并写入日志文件"""
if not os.path.exists(LOG_FILE):
open(LOG_FILE, "w").close()
with open(LOG_FILE, "r") as log_file:
while True:
if stop_reading_flag:
break
line = log_file.readline()
if not line:
socketio.sleep(0.1)
else:
load_status_from_string([line])
socketio.emit("log_append", {
"line": line
})
未实现的内容:
- 想采用 mkfifo 创建管道的方式来替代原有的读取日志文件的方式,但由于 pipe 需要持续监听,在设计上 tmux 和后端是解耦的,一旦后端终止,pipe 也会断开,导致无法持续监听日志输出。因此最终还是采用了定时读取日志文件的方式。
5. 服务器终端交互
5.1. 判断是否存在会话
def tmux_session_exists():
result = subprocess.run(
["tmux", "has-session", "-t", TMUX_SESSION],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL
)
return result.returncode == 0
5.2. 启动与退出
启动是使用tmux new-session而不是tmux new,这样可以保证当 unturned 的寄生终端退出后,tmux 会话也会自动关闭。
cmd = RUN_SCRIPT + f" active_save={active_save}"
if update:
cmd += " update=1"
result = subprocess.run(
["tmux", "new-session", "-s", TMUX_SESSION, "-d", cmd]
)
def tmux_send(cmd):
subprocess.run(
["tmux", "send-keys", "-t", TMUX_SESSION, cmd, "Enter"],
check=False
)
# 退出
send_tmux_command("shutdown")
6. 存档管理
主要分为上传、下载、删除、备份、回档。存档其基本结构为:
Servers/
├── SaveA/
│ ├── Bundles
│ ├── Config.json
│ ├── Config.txt
│ ├── Level
│ ├── Maps
│ ├── Server
│ ├── Workshop
│ └── WorkshopDownloadConfig.json
├── SaveB/
6.1. 上传
@api.route("/upload-save", methods=["POST"])
def upload_save():
if "file" not in request.files:
return jsonify({"error": "No file"}), 400
file = request.files["file"]
if not file.filename.endswith(".zip"):
return jsonify({"error": "Only zip allowed"}), 400
file.seek(0, os.SEEK_END)
size = file.tell()
if size > 4 * 1024 * 1024:
return jsonify({"error": "File too large"}), 400
file.seek(0)
with tempfile.TemporaryDirectory() as tmpdir:
zip_path = os.path.join(tmpdir, "upload.zip")
file.save(zip_path)
with zipfile.ZipFile(zip_path) as z:
z.extractall(tmpdir)
entries = os.listdir(tmpdir)
entries.remove("upload.zip")
# 确保 zip 中只有一个根目录
if len(entries) != 1:
return jsonify({"error": "Zip must contain exactly one root directory"}), 400
root_dir_name = entries[0]
extracted_dir = os.path.join(tmpdir, root_dir_name)
# 处理 zip 名称与文件夹名不同的情况
if root_dir_name != file.filename[:-4]:
shutil.move(extracted_dir, os.path.join(tmpdir, file.filename[:-4]))
extracted_dir = os.path.join(tmpdir, file.filename[:-4])
# 确保文件夹中有 Config.txt
if not os.path.exists(os.path.join(extracted_dir, "Config.txt")):
return jsonify({"error": "Missing Config.txt in root directory"}), 400
save_name = file.filename[:-4] # 不带扩展名的文件名
dst = os.path.join(SAVES_DIR, save_name)
if os.path.exists(dst):
return jsonify({"error": "Save already exists"}), 400
# 保存文件
shutil.move(extracted_dir, dst)
return jsonify({
"message": f"Save {save_name} uploaded successfully",
"save_name": save_name
})
async function uploadSave() {
const file = document.getElementById("uploadFile").files[0];
if (!file) {
toast("请选择文件", "error");
return;
}
if (!file.name.endsWith(".zip")) {
toast("仅支持上传.zip文件", "error");
return;
}
if (file.size > 4 * 1024 * 1024) {
toast("文件过大,最大支持4MB", "error");
return;
}
const formData = new FormData();
formData.append("file", file);
// 检查存档是否重复
if (serverStatus.saves.includes(file.name.split(".")[0])) {
toast("存档名重复,请选择其他存档名", "error");
return;
}
try {
const response = await request.post("/upload-save", formData, {
headers: {
"Content-Type": "multipart/form-data",
},
});
toast("上传成功", "success");
refreshSaves(response.data.save_name); // 刷新存档列表
} catch (error) {
toast("上传失败", "error");
}
}
6.2. 下载
这里的下载直接从备份里下载。
@api.route("/download-backup", methods=["GET"])
def download_backup():
save_name = request.args.get("save_name")
backup_name = request.args.get("backup_name")
if not save_name or not backup_name:
return jsonify({"error": "Save name and backup name are required"}), 400
backup_path = os.path.join(SAVES_DIR, save_name, "Backup", backup_name)
if not os.path.exists(backup_path):
return jsonify({"error": "Backup not found"}), 400
# 创建临时zip文件
temp_zip = tempfile.NamedTemporaryFile(delete=False, suffix=".zip")
with zipfile.ZipFile(temp_zip.name, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, dirs, files in os.walk(backup_path):
for file in files:
file_path = os.path.join(root, file)
arcname = os.path.relpath(file_path, backup_path)
zipf.write(file_path, arcname)
temp_zip.close()
def generate():
with open(temp_zip.name, 'rb') as f:
while True:
data = f.read(4096)
if not data:
break
yield data
os.remove(temp_zip.name)
response = app.response_class(generate(), mimetype='application/zip')
response.headers.set('Content-Disposition', 'attachment', filename=f"{backup_name}.zip")
return response
function downloadBackup(backupName) {
request.get('/download-backup', {
params: {
save_name: backupTableData.currentSave,
backup_name: backupName
},
responseType: 'blob'
})
.then(res => {
// 默认文件名
let filename = `${backupName}.zip`;
// 尝试从 Content-Disposition 解析
const disposition = res.headers['content-disposition'];
if (disposition) {
const match = disposition.match(/filename="?([^"]+)"?/);
if (match) {
filename = decodeURIComponent(match[1]);
}
}
// 创建下载
const blob = new Blob([res.data], { type: 'application/zip' });
const url = window.URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = filename;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
window.URL.revokeObjectURL(url);
})
.catch(err => {
toast(err.response?.data?.error || '下载失败', 'error');
});
}
6.3. 删除
删除直接使用 shutil.rmtree 删除存档目录。
6.4. 备份
unturned 本身并没有提供存档备份功能,所以需要自己实现。主要思路是将当前存档目录下的内容复制到一个以时间命名的备份目录中。我之前这篇Unturned自动备份脚本写过使用纯 Bash 脚本实现的备份功能,这里直接借鉴了其中的思路,并用 Python 重写。
备份需要排除一些不必要的文件夹,不备份Steam Workshop 内容(体积巨大)以及Backup 目录本身(避免递归)。
exclude_dirs = {"Workshop", "Backup"}
备份时,直接在存档目录下创建一个 Backup 目录,然后在该目录下创建以时间命名的备份文件夹,最后将存档内容复制进去。备份时需要限制最大备份数量,超过后删除最早的备份。
def backup_save():
save_name = server_status["active_save"]
if not save_name:
return
print(f"Backing up {save_name}...")
# 游戏目录
source_dir = os.path.join(SAVES_DIR, save_name)
timestamp = time.strftime("%Y-%m-%d_%H-%M-%S", time.localtime())
# 创建备份目录
backup_dest = os.path.join(SAVES_DIR, save_name, "Backup", timestamp)
os.makedirs(backup_dest, exist_ok=True)
# 执行备份
exclude_dirs = {"Workshop", "Backup"}
copytree_with_exclusions(source_dir, backup_dest, exclude_dirs)
# 删除超过最大数量的备份
clean_old_backups(save_name)
定时自动备份:
from apscheduler.schedulers.background import BackgroundScheduler
backup_scheduler = BackgroundScheduler()
backup_scheduler.add_job(backup_save_scheduler, 'interval', minutes=BACKUP_INTERVAL_MINUTES)
# 如果服务器正在运行,则启动自动备份
backup_scheduler.start()
6.5. 回档
回档则是将某个备份目录的内容复制回存档目录,覆盖当前存档内容。在复制前需要确保该存档未被使用(服务器未运行)。
7. 其他待改进的功能
由于本项目仅用于个人和朋友的使用,功能相对简陋,有些安全方面的都简化了,比如:
- 身份验证仅用一个简单的密码,用于简单防止网上某些恶意扫描器。
- 上传文件没有做严格的校验,
z.extractall直接解压到存档目录,存在被构造路径穿越攻击的风险。
8. 界面演示